- 製品機能
- Webアプリケーションサーバー監視
- データベース監視
- エンドユーザー体感監視
- 仮想化環境監視
- コンバージドインフラストラクチャ
- クラウド環境監視
- ミドルウェア/ポータル監視
- Webトランザクション監視(APMインサイト)
- サーバー監視
- Web監視
- サービス監視
- メールサーバー監視
- ERP監視
- その他の監視
- その他
- 新機能の紹介
- 製品情報
- Edition
- 体験サイト
- 動作環境
- ドキュメント
- サポート
- テーマ別の解説情報
- APM
- データベース監視
- エンドユーザー体感監視
- Web監視
- その他の監視
- その他
- 関連製品

簡単なHadoopの監視
大規模なデータセットの分散ストレージと分散処理は、IT管理者にとって常に課題でした。大規模なデータセットを効率的に格納および処理する必要性が高まり、Hadoopフレームワークが効率的に開発されました。膨大なストレージ容量と処理能力を備えたHadoopにより、ユーザーは絶えず増加するデータセットを管理し、タスクを簡単に実行できます。ただし、Hadoopフレームワークのスムーズな機能を確保することが重要です。Applications Managerでは、Hadoop環境に関する操作上の洞察を簡単に取得したり、REST APIまたはJMXを介してHadoopクラスタに接続したり、分散Hadoopクラスタの最適な正常性状態を維持したり、クラスタが利用可能でありタスクを迅速かつ正確に処理することを確保することができます。
Hadoopクラスタの全体的な正常性が追跡可能です。
- Hadoopシステムの可用性と状態を監視します。
- 分散ファイルシステム(DFS)の統計情報(DFS容量、使用済み領域、空き領域、DFS以外の使用済み領域)を理解
- ファイルとディレクトリの増加を追跡し、ファイル数の異常増加による潜在的な問題の防止。
- ブロックの状態(不足、破損など)を追跡して、データがHadoop DFS全体に最適に格納されていることを確認。
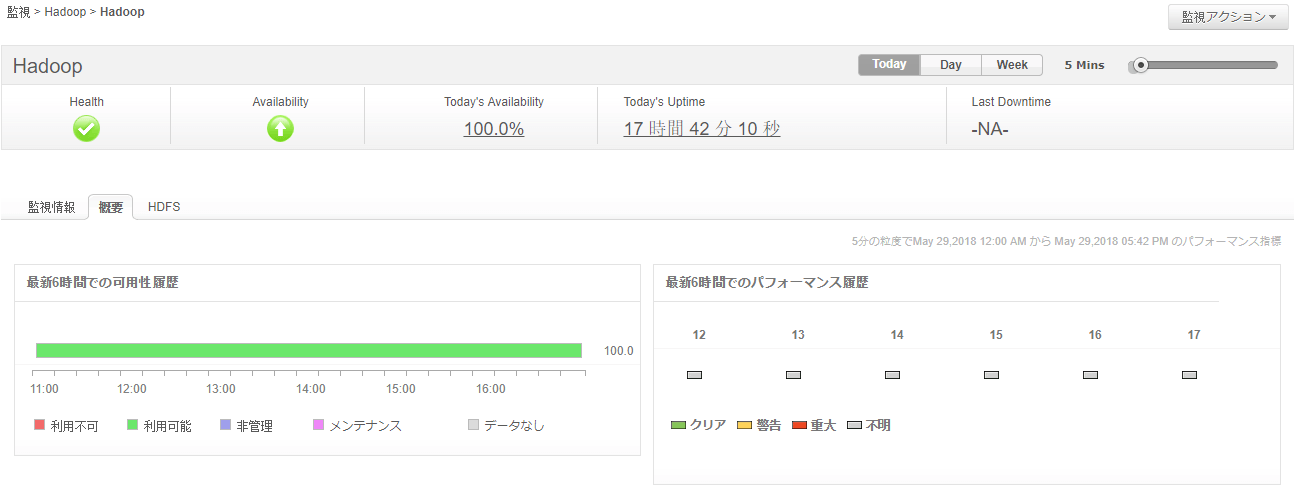 アプリケーションマネージャーは、ハープクラスターの全体的な健全性を追跡することができます
アプリケーションマネージャーは、ハープクラスターの全体的な健全性を追跡することができますHadoop分散ファイルシステム(HDFS)を監視。
- NameNode JVMとOSのステータスを追跡することによって、HDFSの容量と使用トレンドを理解。
- しきい値に違反したときに通知を受け取る。
- 個々のデータノードの状態を監視し、ダウンしたときに即時通知を取得。
- HDFSメモリーを追跡し、メモリー不足の場合に通知を受ける。
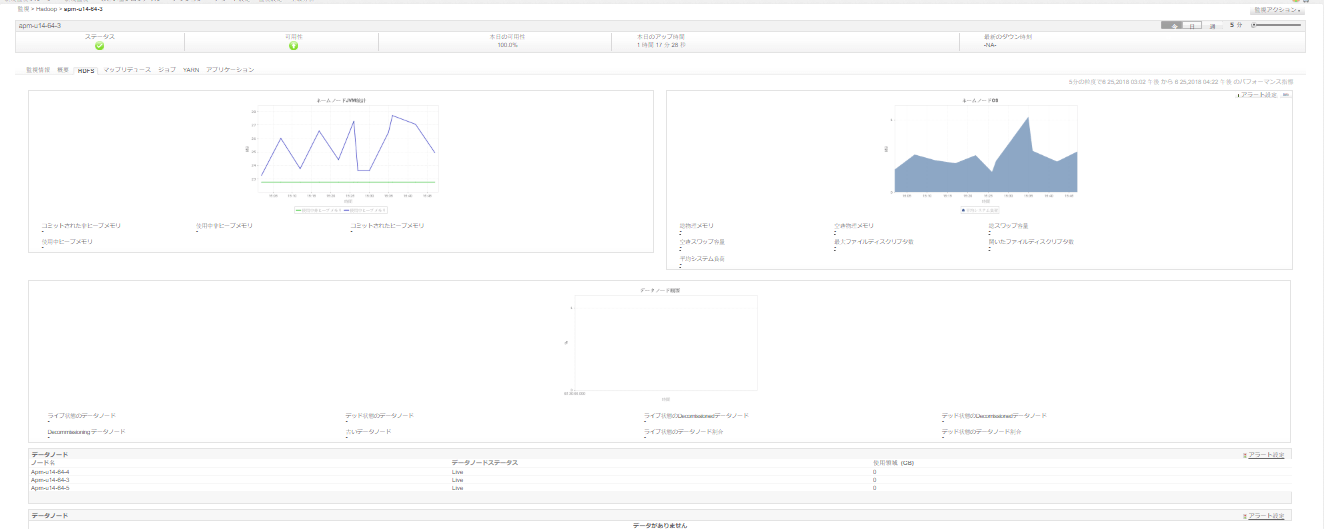 アプリケーションマネージャはhadoop分散ファイルシステムを監視します
アプリケーションマネージャはhadoop分散ファイルシステムを監視しますタスクトラッカーまたはノードマネージャーのパフォーマンスを理解。
- Hadoop MapReduceのHadoopバージョン1.xにおけるタスクトラッカーとスロットの状態(動作状態、停止、グレーリスト済みなど)を追跡。
- キューの状態を表示して、タスクが完全に実行されているか、キューが停止しているかどうかを判断。
- バージョン2.xでは、Hadoop Yarnからノードマネージャーのパフォーマンスを追跡。
- アクティブ、廃止、不健全、紛失など、さまざまな状態におけるノード数の把握。
ジョブやアプリケーションの状態を簡単に追跡。
- 常に一定の時間に実行されているジョブまたはアプリケーションの数を把握。
- すべてのジョブまたはアプリケーションを状態別にソート。
- 失敗したジョブまたはアプリケーションの数に関する通知を受け取り、必要な是正措置を講じることが可能。
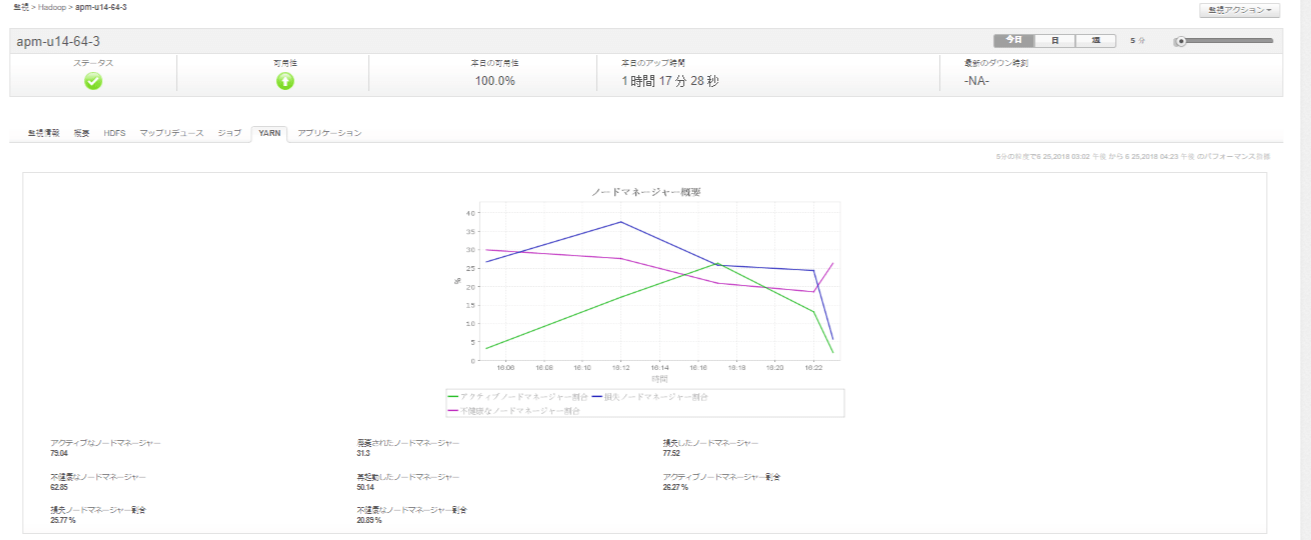 ハープマップ
ハープマップ アプリケーションマネージャはジョブとアプリケーションの状態を簡単に追跡できます
アプリケーションマネージャはジョブとアプリケーションの状態を簡単に追跡できます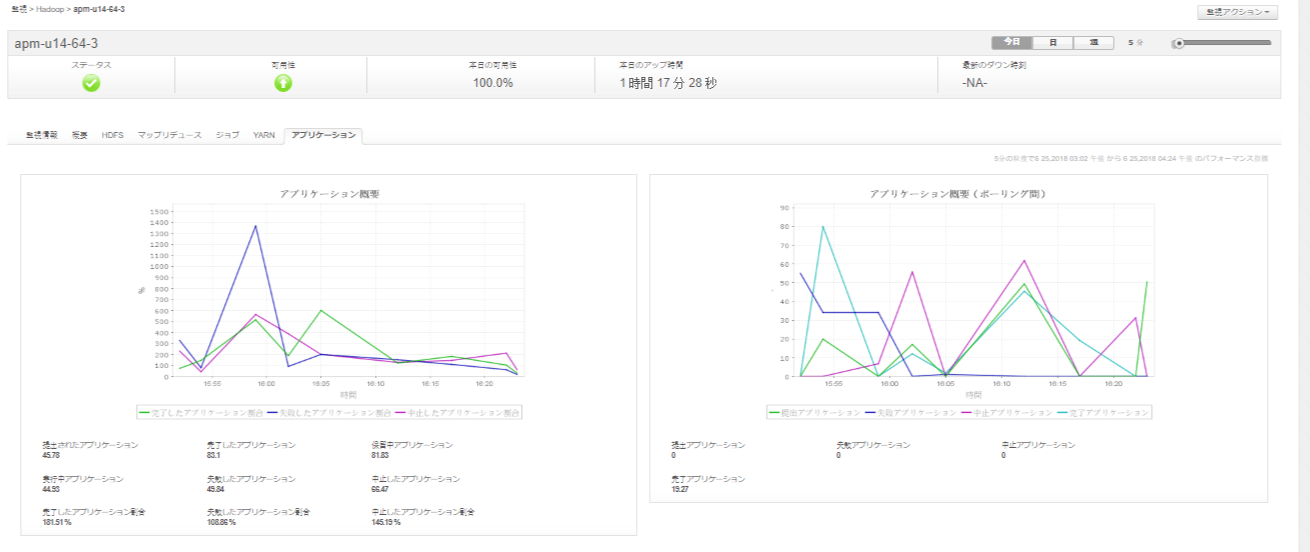 アプリケーションマネージャはジョブとアプリケーションの状態を簡単に追跡できます1
アプリケーションマネージャはジョブとアプリケーションの状態を簡単に追跡できます1レポート生成およびダッシュボード。
強力な情報を指先で操作。Hadoopクラスタのリソースの使用率とパフォーマンスを、リアルタイムおよび履歴データを示す事前作成されたレポートとダッシュボードで視覚化。