- 製品機能
- Webアプリケーションサーバー監視
- データベース監視
- エンドユーザー体感監視
- 仮想化環境監視
- コンバージドインフラストラクチャ
- クラウド環境監視
- ミドルウェア/ポータル監視
- Webトランザクション監視(APMインサイト)
- サーバー監視
- Web監視
- サービス監視
- メールサーバー監視
- ERP監視
- その他の監視
- その他
- 新機能の紹介
- 製品情報
- Edition
- 体験サイト
- 動作環境
- ドキュメント
- サポート
- テーマ別の解説情報
- APM
- データベース監視
- エンドユーザー体感監視
- Web監視
- その他の監視
- その他
- 関連製品

Apache Spark監視
データ処理フレームワークです。Apache Sparkには、非周期的なデータフローとメモリー内コンピューティングをサポートする高度なDAG実行エンジンがあります。SparkはHadoop、Mesos、スタンドアロン、またはクラウド上で動作します。HDFS、Cassandra、HBase、S3などのさまざまなデータソースにアクセスできます。
スパーク・アプリケーションは、多くのコンポーネントが組み合わせて動作させています。運用環境にSparkを導入する予定がある場合、Applications Managerではさまざまなコンポーネントを監視し、パフォーマンスパラメータを理解し、問題が発生したときにアラートを生成し、問題をトラブルシューティングすることができます。
Sparkのパフォーマンスの可視化
データパイプラインとアプリケーションのサービストポロジ全体を自動的に検出。リアルタイムの完全なクラスタおよびノード管理、およびワークフローの視覚化によるSparkアプリケーション実行の監視を実行します。スタンドアロン・モードでは、クラスタ内で作成されたすべてのアプリケーションについて、個々のノードおよび実行プログラムのプロセスで実行されているマスタおよびワーカーを視覚化します。クラスタ・ランタイム・メトリクス、個々のノード、および構成に関する最新の情報を得ることができます。
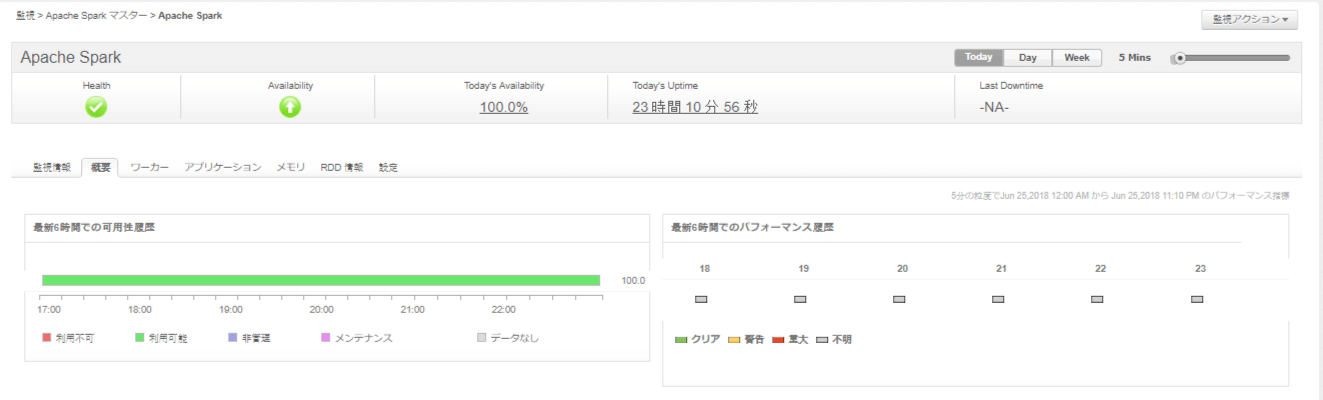 スパークの概要
スパークの概要リソース使用率の追跡
Sparkアプリケーションが最適に動作するようにリソースを管理します。新しいジョブを追加する場合、運用チームは利用可能なリソースとビジネス優先順位のバランスを取る必要があります。ディスクI/Oからメモリー使用量のメトリクスや、すべてのノードにおける正常性(リアルタイム)やCPU使用率、並びにJVMヒープ占有率などのきめ細かなパフォーマンス統計を使用して、クラスタの健全性を維持します。
 メモリ使用率
メモリ使用率Sparkコアとアプリケーションの理解を深める
Spark生産アプリケーションのメトリクスの把握、ユーザー定義のデータに基づいたSparkアプリケーションの構成およびセグメント化や状態(アクティブ、待機中、完了済み)と実行時間に基づいたアプリケーションのソート分別を実行することが可能です。ジョブが失敗すると、原因は通常コアが不足しているためです。Sparkノードやワーカー監視は、空きコア数と使用中コア数を含むメトリックを提供し、ユーザーはコアに基づいてリソースを割り当てることができます。
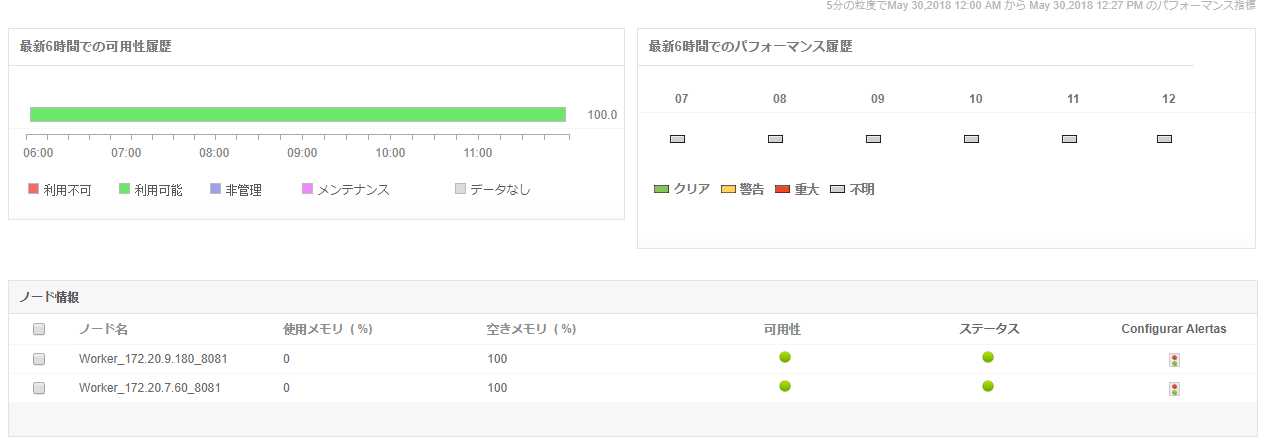 Sparkコアとアプリケーション理解
Sparkコアとアプリケーション理解RDDとカウンタのパフォーマンスの理解
指定されたアプリケーションの格納されたRDD(弾力性のある分散データセット)、特定のRDDのストレージ状態とメモリー使用率、Spark実行ごとのすべてのSparkカウンタなどのパフォーマンスメトリクスを取得します。潜在的なパフォーマンスの最適化のために、ファイルレベルのキャッシュヒットと並列リスティングジョブに対する深い洞察を取得します。
 RDDカウンタの性能理解
RDDカウンタの性能理解パフォーマンス問題野より迅速な修正
Apache Sparkのコンポーネントにパフォーマンス上の問題がある場合は、すぐに通知を受け取れます。パフォーマンスのボトルネックを認識し、どのアプリケーションが過負荷を引き起こしているかを確認。エンドユーザーが問題を経験する前に迅速な是正措置を実施します。